Una IA publica 11.000 podcasts al día copiando a periodistas locales. Y de momento no hay forma de parar la avalancha
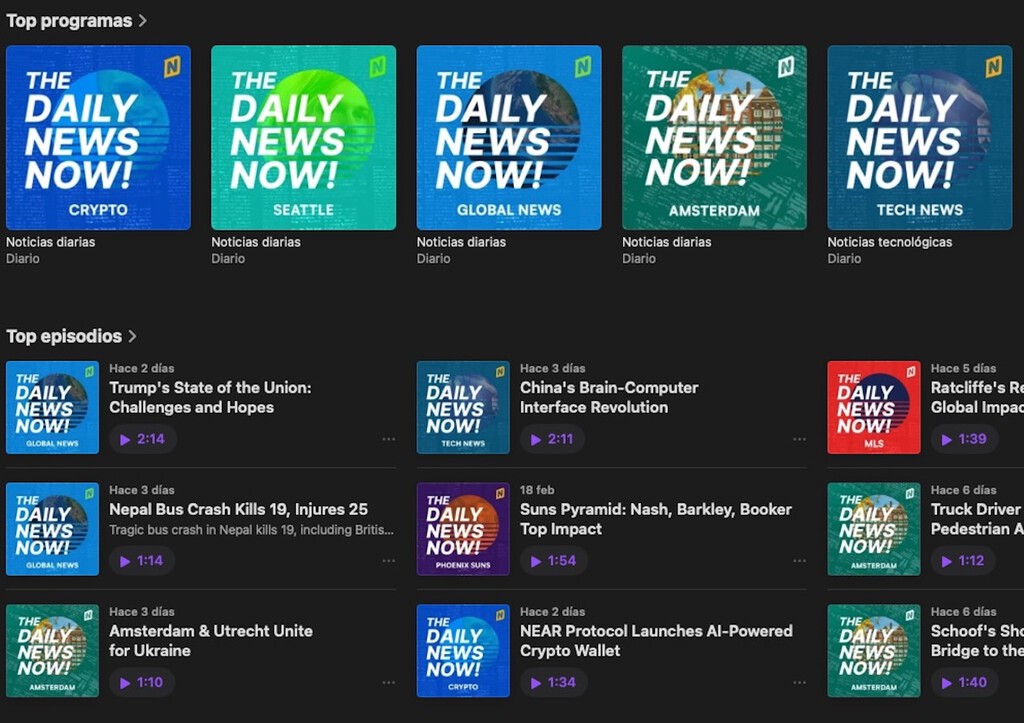
Una red de podcasts automatizados publica más episodios en 24 horas que muchas emisoras en un año, usando IA para convertir artículos periodísticos en audio en cuestión de minutos. Un caso específico, el del canal 'The Daily News Now!', nos sirve para plantearnos hasta dónde puede llegar el scraping de contenido en la era de la IA generativa. A saquear. El caso lo puso sobre la mesa Indicator : el 31 de enero, a las 2:57 de la tarde, el diario 'The Chronicle' (una publicación completamente marginal: pese a tener ya 120 años de edad, lo publica la universidad de Duke, en Durham, y está dirigido y elaborado íntegramente por alumnos) publicó un artículo sobre Gemma Tutton, estudiante y saltadora de pértiga que había ganado una competición universitaria. Diecisiete minutos después, un podcast llamado 'Durham News Today' subía a Spotify un episodio titulado 'El triunfante regreso de Gemma Tutton al salto con pértiga'. El podcast, por descontado, no tenía ninguna vinculación con el periódico. Pero reproducía casi todos los datos del artículo original en el mismo orden, incluyendo frases prácticamente idénticas. Y no es un caso aislado: 'Durham News Today' es uno de los al menos 433 programas que integran 'The Daily News Now!' red de podcasts creada por Corey Cambridge. Desde el 23 de enero, 'DNN' ha publicado más de 350.000 episodios (aproximadamente 11.000 al día). En Xataka Ocho personas. Una hora de trabajo. Un dólar de presupuesto. 5.000 nuevos podcasts gracias a la IA Cómo lo hacen. Obviamente, con IA: un sistema de scraping (automatización mediante software que extrae grandes volúmenes de contenido) monitoriza webs de medios, extirpa el texto de los artículos publicados, lo procesa mediante herramientas de síntesis de lenguaje natural, lo convierte en audio y lo distribuye en plataformas como Spotify. Todo en cuestión de minutos. Y no se molestan en disimular: según Indicator, reproducen la estructura, los datos y la redacción de piezas publicadas por medios como afiliadas locales de Fox y NBC, 'TechCrunch', 'Toronto Star', 'The Verge' o la emisora 'WRAL'. Las herramientas. Para entender por qué una operación de este tipo es técnicamente posible hoy hay que echar un vistazo al ecosistema de herramientas que lleva dos años democratizando la producción de audio sintético. En septiembre de 2024, Google activó globalmente la función Audio Overview de NotebookLM . La herramienta convierte cualquier documento subido por el usuario en un resumen en audio. El impacto fue inmediato: NotebookLM pasó de 652.000 visitas mensuales en agosto de ese año a 10,5 millones en septiembre, un aumento del 371% en treinta días . En los tres meses siguientes al lanzamiento global, los usuarios acumularon audio con una duración total superior a 350 años de reproducción continua . NotebookLM normalizó la idea del podcast sintético, y desde ahí, todo fue cuesta abajo. ElevenLabs , especializada en síntesis de voz y valorada en más de mil millones de dólares, lanzó en diciembre de 2024 su función GenFM, que permite generar episodios completos a partir de texto. Wondercraft , financiada en parte por ElevenLabs, introdujo soporte para editar podcasts generados con NotebookLM. Podcastle, orientada a creadores de podcasts, incorporó generación de voz con texto para completar o sustituir fragmentos de locución. El secreto: el precio. En un análisis de una red similar ( Inception Point AI , que genera en torno a 3.000 episodios semanales con más de cincuenta locutores por IA) producir un episodio cuesta aproximadamente un dólar, y con apenas 20 oyentes el episodio resulta rentable gracias a la publicidad programática. El modelo no busca audiencias leales, sino posicionamiento en buscadores: publicando episodios hiperespecíficos sobre ciudades o temas de nicho minutos después de que los medios locales lancen sus artículos, estas redes se adelantan a la capacidad de los humanos para la inmediatez informativa. Dicho de otro modo: 'The Daily News Now!' aparece en los primeros resultados de Spotify en búsquedas de noticias locales en decenas de ciudades estadounidenses. Compite directamente (y en muchos casos supera) a los medios a los que roba contenido. En Xataka NotebookLM: qué es, cómo funciona y cómo usar la IA de Google para organizar fuentes de información o crear podcasts en minutos Temas legales. Cambridge se defiende diciendo que su red solo accede a "información pública disponible", y se limita a resumirla. Pero Indicator encontró casi treinta episodios de 'Durham News Today' que reproducían la estructura, el orden y frases concretas de artículos de 'The Duke Chronicle': no es un patrón puntual. Y puede que aún así, legalmente Cambridge esté protegido, pero el problema alude más bien a la ética de la información que a los detalles legales. En cualquier caso, en mayo de 2025, la Oficina de Copyright de Estados Unidos llegó a la conclusión de que un material "públicamente accesible" no necesariamente es de libre uso. Hay precedentes legales en esa dirección: en noviembre de 2025, una jueza federal de Nueva York no desestimó la demanda de catorce grandes editores (entre ellos Forbes, The Atlantic y Los Angeles Times) contra la empresa de IA Cohere, al considerar que sus resúmenes podían constituir infracción directa si reproducían "estructura, secuenciación, tono y elecciones expresivas" de los artículos originales. Por el contrario, en abril del mismo año, el caso NYT vs. Microsoft descartó las demandas relacionadas con los resúmenes generados por Copilot por considerar que no eran "sustancialmente similares" a los artículos de origen. Mientras, y aún sin juicio , está el caso del New York Times contra OpenAI y Microsoft, acusados de usar contenido periodístico para entrenar sus modelos Muy avispados. Hay otro detalle: no estamos hablando del 'New York Times', sino que 'DNN' concentra su producción en noticias de nicho local (atletismo universitario, consejos estudiantiles, gatos atrapados en árboles), primero porque esos contenidos generan búsquedas específicas con poca competencia en Spotify. Y segundo, porque legalmente es más seguro. Apuntan a modelos de periodismo más frágiles. Mientras tanto, distribuidores como Spotify desarrollan herramientas para detectar música artificial (eliminó más de 75 millones de pistas ), pero el siguiente paso es concienciar a las grandes marcas de que no se beneficien de la explotación de redacciones que no pueden defenderse. En Xataka | La IA ya es un campo de batalla: Anthropic acaba de acusar a DeepSeek y a otras empresas chinas de “destilar” Claude - La noticia Una IA publica 11.000 podcasts al día copiando a periodistas locales. Y de momento no hay forma de parar la avalancha fue publicada originalmente en Xataka por John Tones .