 동아일보
동아일보
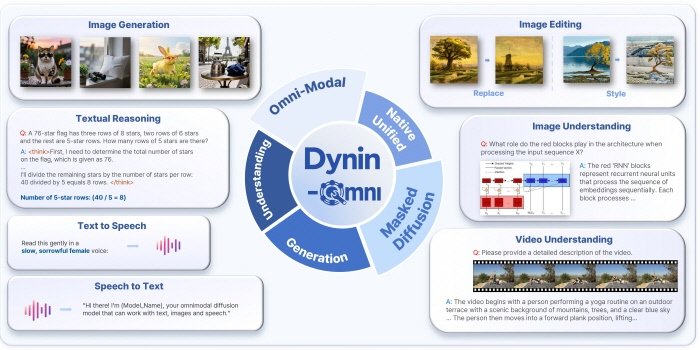
서울대 공대 전기정보공학부 도재영 교수 연구팀(AIDAS 연구실)은 글자, 사진, 영상, 소리를 하나의 모델이 동시에 이해하고 생성할 수 있는 차세대 인공지능(AI) 파운데이션 모델 ‘Dynin-Omni’를 개발했다고 밝혔다. 연구진은 AI 모델이 다양한 감각 정보를 동시에 처리할 수 있는 구조를 설계해, 정보를 순차적으로 생성하는 기존 방식의 문제점을 해결했다고 설명했다. 글자부터 영상까지 다양한 정보를 단일 모델이 함께 처리하는 옴니모달(Omnimodal) AI를 구현했다는 설명이다. 최근 AI는 텍스트뿐 아니라 이미지, 음성, 영상 등 다양한 형태의 데이터를 처리하는 방향으로 발전하고 있다. 다만 실제 환경에서 사람과 자연스럽게 상호작용하기 위해서는 단순 정보 인식을 넘어 복합적인 처리 능력이 요구된다. 예를 들어 음성을 인식해 이미지를 생성하거나, 영상을 분석해 음성으로 설명하는 기능은 여러 감각 정보를 동시에 활용하는 통합적 처리 구조가 필요하다. 기존 AI 시스템은
Go to News Site