
iPadOS 26.4 RC available now, and public launch soon
Apple just shipped the RC (Release Candidate) version of iPadOS 26.4 for testing, which means the public launch is coming very soon. Here are the details. more…
Apple just shipped the RC (Release Candidate) version of iPadOS 26.4 for testing, which means the public launch is coming very soon. Here are the details. more…

Microsoft ruminating on suing OpenAI over Altman's recent deal with Amazon

We just got our first trailer for Spider-Man: Brand New Day , the next big Marvel film. This is the fourth installment led by Tom Holland and follows the multiversal shenanigans of Spider-Man: No Way Home . I'm about to get into some spoilers, for those still working through the MCU catalog. No Way Home ended with the entire world forgetting about the existence of Peter Parker, so this new movie will deal with the fallout from that. His whole support system is gone, though it looks like he still checks in on besties MJ and Ned from time to time. Peter Parker may be lonely, but he's not alone in the film. He's teaming up with the Punisher, who is still played by Jon Bernthal after returning to the role in Daredevil: Born Again . In the comics, Spider-Man and the Punisher are long-time work buddies and occasional sparring partners. As a matter of fact, Frank Castle made his introduction in a Spider-Man comic that was published in 1974. Bruce Banner also shows up in the trailer, potentially as Parker's professor. Mark Ruffalo is returning to the role, but we don't have any confirmation that he'll turn into the Hulk. It's worth pointing out that this is the regular human Banner, and not the hybrid version that's been popping up in recent MCU projects. The trailer even highlights an iconic Spider-Man villain. Michael Mando is playing Scorpion, which is a pretty deep MCU cut. The character was teased all the way back in Spider-Man: Homecoming . The footage also shows Spidey battling ninjas that look suspiciously like the Hand, who were last seen in The Defenders on Netflix . This lends credence to rumors that Daredevil could be appearing in the film . We don't have all that long to wait. Spider-Man: Brand New Day premieres in theaters on July 31. This is the final MCU film before the long-awaited Avengers: Doomsday , which hits cinemas in December. This article originally appeared on Engadget at https://www.engadget.com/entertainment/tv-movies/the-spider-man-brand-new-day-trailer-is-filled-with-mcu-cameos-170215452.html?src=rss

The post The Roborock Saros 20 Sees More, Cleans More, and Stops at Nothing appeared first on Android Headlines .

Reviewed on: PC Platform: PlayStation 5, Xbox Series X/S, PC, Mac Publisher: Pearl Abyss Developer: Pearl Abyss Release: March 19, 2026 Rating: Mature The first meal you learn to cook in Crimson Desert is Clear Soup, a brothy mixture of simply water, meat, and lentils. It looks nice and is probably filling, but would no doubt be a bit simple and leave you wanting something with a little more depth of flavor. As it turns out, it’s the perfect allegory for Crimson Desert at large: a beautiful, exploration-rich open-world game that’s a clear technological achievement, hampered by a cornucopia of little frustrations and a stark lack of narrative depth. In Crimson Desert, you follow the exploits of Kliff, the leader of a sort of fantasy peacekeeping corps known as the Greymanes, who help with the safety of the country of Pailune. But after an ambush, the company is scattered, and Kliff is killed, only for him to be revived by supernatural beings and set on a path to save the world from dark forces. There’s a grand fantasy world to explore in Crimson Desert, filled with fascinating little cultures and wondrous sights – from a clockwork city where machine beings tend nearby farms, to a labyrinth of esoteric ruins floating in the sky. Crimson Desert is a visual and technical marvel at every turn, a beautifully realized world from a pure aesthetic standpoint. The entire world is rendered as one location, and you can, quite literally, see every inch of it from any high point. It’s breathtaking. But the first major downside that becomes quite apparent early on is that the game doesn’t have much of a story to tell or any major themes to impart. I can’t think of a better way to describe Crimson Desert’s main story, other than it’s simply a mess. The plot fluctuates from hard to follow to downright nonsensical at times, more focused on delivering a sense of spectacle and bombast than anything. But it also clearly wants to have these big emotional moments that are supposed to have some kind of payoff that just isn’t there. The best way to describe it is if you looked up a compilation of “Game of Thrones’ best moments” on YouTube. So you get all these admittedly cool sequences and big fantasy set pieces, but without any of the backing of real character growth and depth. That even applies to the main character, Kliff himself, who feels just one step removed from a silent protagonist. This means that despite the beauty of the world, there’s nothing to ground you in it or make you truly care about the things you’re doing. The one exception here is reuniting all of the Greymanes, where the game’s sole emotional core lies. Seeing your camp come together and grow is undeniably satisfying, and there are some meaningful moments of bonding between Kliff and his allies. But the game makes all of this optional about a third of the way through – meaning you might miss most of it. You’ll likely see a lot of comparisons between Crimson Desert, Breath of the Wild, and Dragon’s Dogma. The inspiration from those two titans of open-world games is clear, as Crimson Desert similarly has a minimalistic approach to everything. There are very few tutorials, requiring you to learn everything through experimentation and practice. The game doesn’t have any immediately available fast travel, instead requiring you to discover fast travel points through exploration. And there’s a heavy focus on puzzle-solving, using your myriad skills. There are so many different features and mechanics in Crimson Desert that there’s no way I can properly describe everything. This is a game that wants to be everything, the textbook definition of an open-world. You have base building and soldier management as you rebuild the Greymanes. There’s crunchy melee combat that even integrates absurd wrestling moves. Realistic physics and complex Zelda-esque puzzles are scattered throughout the world. One encounters hundreds of little sidequests and contained stories to discover. Uncover dynamic relationship systems where you can bond with animals and NPCs. And there’s even dragon riding. The number of things to see and do in Crimson Desert is utterly overwhelming. But there’s a real sense of discovery baked into the fabric of the world that’s unbelievably compelling. The quiet moments as I roamed the lands of Pywel were, by far, my favorite. Discovering a sentient tree with a hat I needed to steal for some magical beings. Or stumbling onto a Spirit Knight boss that, when defeated, unlocked a wild new weapon ability that drastically altered my playstyle. It’s these moments of surprise and wonder that make Crimson Desert shine. But outside of that, unfortunately, the game often feels like it’s simply stretched too thin trying to do too many things and not really refining any singular idea. Take combat, for example. The game’s action combat initially feels frenetic and intense, in line with a straight-up action game, getting drastically more interesting in the late-game when you’ve unlocked a wide array of skills. But before you reach that point where everything’s unlocked, it’s surprisingly tedious. Each enemy you kill typically has a short execution animation that plays out, something that’s not bothersome against a few enemies, but becomes aggravating when you’re trying to take over an area and fighting off 40 enemies. This makes taking over bases a slog. And while there are a handful of enjoyably challenging boss battles, there are just as many, if not more, that are miserable affairs. Bosses have huge, wide-reaching attacks and very short windows for when you can cause damage, compounded by small arenas that plaster a big “return to the battle area” warning if you stray an inch or two in the wrong direction. Crimson Desert really wants you to explore and find Abyss artifacts to upgrade Kliff’s stats and buy new combat abilities, as well as gather resources through mining, woodcutting, and more. And if you aren’t upgrading everything accordingly, you’ll get easily beaten into the ground by bosses, but without a tangible stat or levelling system, it’s hard to tell if you’re actually prepared enough for a given mission or boss. I can confidently say Crimson Desert has some of the most nauseatingly frustrating boss battles I’ve ever encountered, except for the handful that bizarrely can be beaten immediately with very specific gimmicks. The more abilities you unlock, the messier combat can get, too, as you have over a dozen different button presses to keep track of for specific attacks. Then there’s the healing system, as the only way Kliff can heal is with food in his inventory, or meals you’ve cooked at bonfires. But bosses make you blow through your food items, meaning you’re constantly on the hunt for new food, spending hours gathering items and cooking them up. And therein lies the crux of my major issue with Crimson Desert – how much of the game feels like it’s simply wasting your time. It’s a game I played for 100 hours that probably should have been more like 50 to 60. That’s largely because, like with the cooking, nearly every facet of the game feels intentionally designed to drag things out in a way that’s not enjoyable in the slightest. I appreciate the emphasis on exploration, but that lack of easy fast travel gets truly aggravating when you’re spending 20 to 30 minutes riding between quests. Locations where you solve puzzles to unveil Abyss artifacts can also be used as fast travel, but only if they’ve been solved. This means if you can’t figure out a puzzle and need to come back later, you won’t get a fast travel point. Similarly, if you want to upgrade your gear, you need to spend time grinding out materials, cutting down trees, hunting for ore, etc. Even the very design of quests feels needlessly drawn out. For example, early in the game, you take a quest to learn how to dye clothes, following an ally to the shop, and then learning that they moved the cauldron you need to the city. You go to the city and use the cauldron, but then have to travel all the way back to the shop to use the dye. A quest that could have quickly been over in a matter of minutes ended up taking me 15, and that’s not an isolated incident – as that kind of design is spread across the entire game. I might not have as much of a problem with it if there were an interesting narrative component, but as I said earlier, there’s nothing truly compelling happening with most of the game’s storytelling. Most of these sidequests you're doing for the tangible items and equipment, or the reward of adding another inventory slot. The limited inventory and management are other issues you constantly have to grapple with, like making frequent trips to towns or camps to unload items. These little frustrations and issues with Crimson Desert quickly start to pile on and add up into something that becomes aggravating. Crimson Desert’s true problem is that it’s simply overdesigned – there are too many moving pieces. Even as in-depth as I’ve gone, there’s still a half-dozen systems I haven’t touched on, like trading and banking. And perhaps most crucially of all, not all of that is fun. I adored running around Pywel and poking my head in ancient ruins, but that enjoyment was constantly brought to a grinding halt by an oppressive boss battle that took me two hours, an inscrutable puzzle with a solution that required an ability I didn’t yet have, or wonky controls that would send me careening off the side of a cliff to my doom, forcing a respawn. And while I didn’t find Crimson Desert to be an overly buggy experience, especially for a game this size, I did have five hard crashes in my time and a handful of bugs, like my wagon getting completely stuck in a building, forcing me to go back to camp and pick the option to retrieve it, then do the mission all over again. I wish Crimson Desert had stripped away some of its superfluous systems, simplified the combat, and really honed in on exploration and puzzle-solving. The quiet moments atop mountain peaks and wandering through bustling city streets, with the little stories therein, are truly something special. However, the game’s lack of a meaningful main narrative and overreliance on padding things out undoubtedly hurt it. But, more than anything, there’s a foundation with Crimson Desert that I hope can be built upon, and considering this is Pearl Abyss’s first single-player game, I wonder how much of this can be chalked up to growing pains. The studio clearly took liberal inspiration from other games, but I hope that there can be something more looking toward the future. Crimson Desert has something special buried beneath its surface, if all those unneeded layers can be cut out. Score: 7 About Game Informer's review system

Here's how to watch Tottenham vs Atletico Madrid in the second leg of the round of 16 Champions League 2025-26.

The last couple of years have seen Mondo expand from limited-edition movie posters and into action figure collectibles, with the studio focusing on '80s and '90s IP specifically. For its next collectible, the company is expanding on its sixth-scale Teenage Mutant Ninja Turtles line, and GameSpot can exclusively reveal the Mondoverse take on Leonardo, the stalwart leader of the shelltastic quartet. Preorders open on March 24, and Mondo will also offer a version of the figure that comes with exclusive accessories. This will be a timed edition, only available from March 24 through April 7. Like the Donatello figure that kicked off the TMNT line last year, Mondo has put its own spin on Leonardo. While the character is instantly recognizable, Mondo has honed in on his ninja training to create a figure that prioritizes stealth and subterfuge. There's still a noble side to the design with a few samurai elements--like a piece of ancient Hamato Yoshi clan leg armor that he wears--while other accessories reflect how the Turtles are forced to make do with whatever parts they can scavenge. If you're not a fan of that look, you can remove the parts and strip Leonardo down so that he has a more traditional '90s-inspired look about him. In case you missed it when preorders first opened up, the first wave of Donatello figures is currently sold out. The Mondoverse spin on the character highlights how Donny has always been the brains of the group, and the figure comes with old-school ninja weapons, alternate heads, swap-out hands, tech gadgets, repurposed mouser droids, and even a fanny pack. The rest of the Mondoverse sixth-scale line has grown considerably over the years, and if you're looking to add something to your shelf, preorders are open for Superman , Batman , X-Men , and Spider-Man figures, all based on their iconic '90s animated series. "What if Leo went down a much more serious path?" "This line is a brand-new take on these characters that merges the styling of the 90’s Turtles movies with the fun of the original animated TV show wackiness. We asked ourselves what what would a mouser look like in a '90s live-action TMNT movie or what would have Donatello’s character evolved to if he had gone full science Donny? We explored all that and more with the Donatello release," Hector Ace, Mondo's senior director of creative and product development, said to GameSpot. "Now that we're at Leonardo, we put that same storytelling effort into every inch of his design. Again, sticking to that classic 90's TMNT vibe, but what if Leo went down a much more serious path? What if he were the only one of the four to take his ninjitsu training seriously and further? What would that look like? If he’s a ninja, he would need to be hidden in the shadows, scaling buildings and hunting for what remains of the foot, or whatever new threats may be coming their way. "We came up with some design elements that would push that very idea: We chose a very shinobi-looking cloak for him, something to give him some aura and mystique. There is still plenty of TMNT Personality worked into these designs. Leo is wearing samurai leg armor that’s been passed down to him from the Hamato Yoshi clan. But he only had one, so he improvised by tying a license plate to his other leg, just to keep the armor motif going. We had some fun with the idea of "why don’t the ninja turtles ever actually dress as ninjas?" If anyone was going to put on a ninja mask, it would be Leo, so we also gave him a swappable ninja mask head." Leo's new scarf adds some extra dramatic posing flair If you'd prefer a more traditional Ninja Turtle, you can remove some accessories The figure can easily hit a dynamic pose Leo's arsenal features a few ninja weapons Donatello has also upgraded Leo's signature swords Leo, admiring Donnie's handiwork As if a giant mutant turtle wasn't scary enough, this mask makes Leo look demonic One of Leo's alternate heads goes full ninja That mouser bot never stood a chance Kunai! Never leave the sewers without a few He's the best there is at what he does, bub We can't wait to see what the rest of the TMNT line looks like

Microsoft AI CEO will focus on developing superintelligence models as Copilot teams come into alignment.

'Send to Miro' makes it easier to move your notes to the computer.

Just $550 until Sunday HP touchscreen laptop with 16GB of RAM and Core i5 processor View Deal I’ve been hunting for affordable laptops for the last few months, specifically because they’re really hard to find. I’ve been leaning a lot on eBay’s certified refurbished program , because it has some of the best deals around. But today I was lucky enough to find one on a new laptop from Best Buy. This HP model has a touchscreen, a Core i7 CPU, and 16GB of RAM for just $549.99 . That’s $250 off. This is definitely still a budget design — it looks like almost identical to the OmniBook series, but doesn’t get that designation, I’m guessing because it’s a model specifically for big box retailers. Even so, the specs inside are more than respectable despite coming with an older processor. The Core i7-1355U is a 10-core model with a 5GHz maximum speed, first released in 2023. Paired with 16GB of RAM and Intel’s Iris Xe graphics, it should handle pretty much everything you can throw at it short of high-end games. 512GB of storage isn’t amazing, should be enough for most users. The screen is particularly notable. At 16 inches and 1080p, it’s not especially sharp, but it does include a touch panel, something rarely seen on a new laptop in the $500 area. The extra space allows for a roomy keyboard with a number pad, great for data entry or students. And while I wish it had a few more ports, USB-C, double USB-A, and HDMI should cover most people’s needs. Just make sure you don’t forget the charger if you leave home — a 45 watt-hour battery with that big screen may not last long. Even HP’s usually generous estimate is just 7.5 hours. Best Buy says this discount is part of its “Tech Fest” promotion, which lasts until Sunday (March 22nd). If you want something a little faster and sleeker but without the touchscreen, there’s a Samsung laptop with almost the same specs but a newer processor at the same price .

AI is writing more code than humans—and much of it isn’t secure. Corridor’s founders think they’ve found a way to catch the mistakes before attackers do.
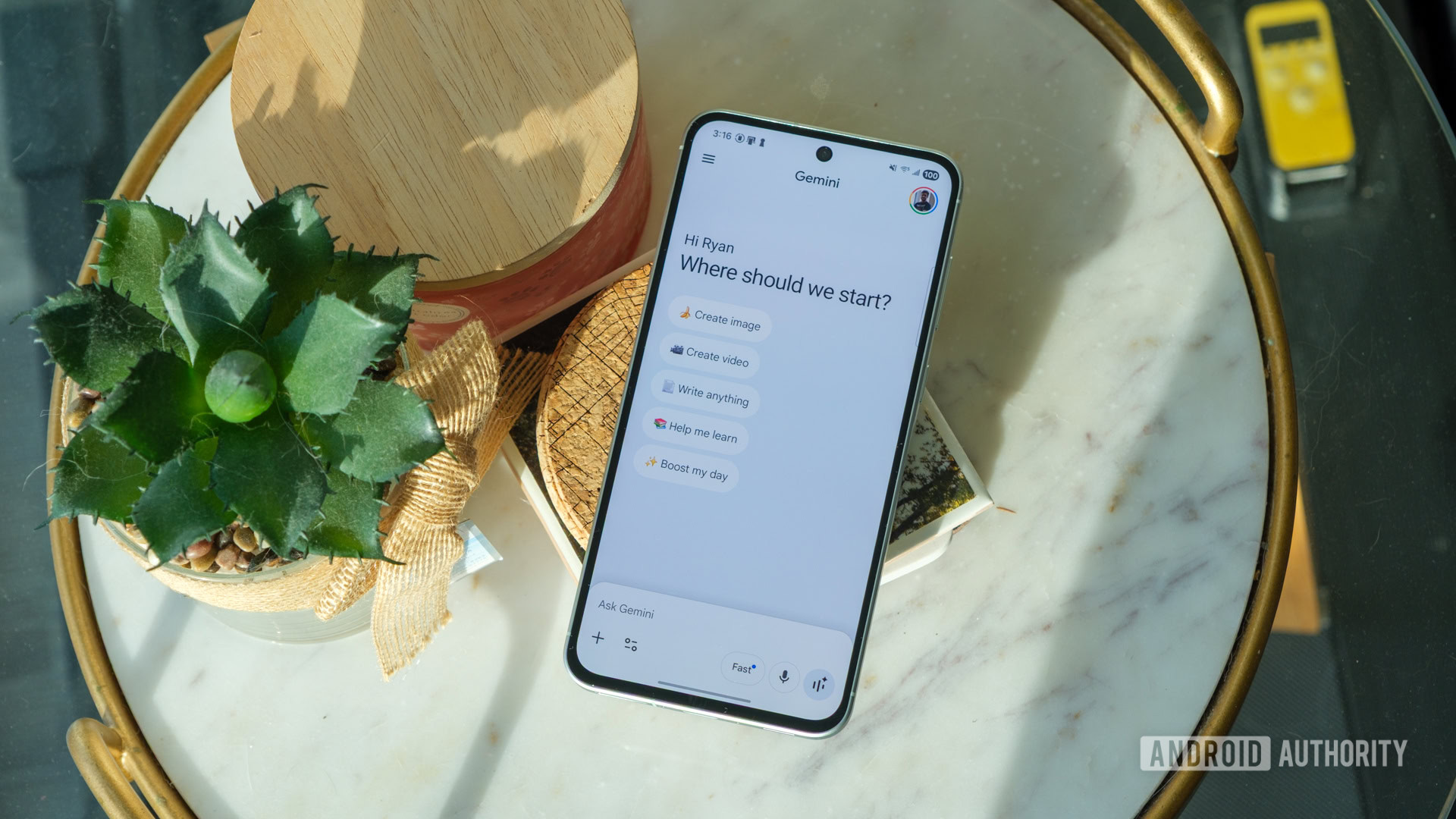
We found changes to the sidebar, overlay controls, and how Gemini shows its thought process in our latest APK teardown.

Madison Mills / Axios : Ramp data: Anthropic is capturing ~73% of all spending among companies buying AI tools for the first time, up from a 50/50 split with OpenAI in January — Anthropic is now capturing over 73% of all spending among companies buying AI tools for the first time, according to customer data from Ramp.

As of March 18, these are the DJI deals on offer ahead of the Amazon Big Spring Sale.

One of the most important aspects of Marathon is its faction upgrades. Sure, its gameplay loop centers on battling UESC soldiers and rival players while securing as much loot as possible. But in order to shift the odds in your favor -- aside from using sound tactics and having better gear -- you’ll need to invest in each faction’s upgrade tree. Marathon has six different factions for you to choose from. That said, most of your early runs will be spent working for CyberAcme; not only are they the first faction you’re introduced to, they also offer a few solid initial upgrades. Your available options will increase once you start unlocking other factions though. If you want to make the most of your time/resources early on (in terms of choosing the best upgrades), then check out our guide below. CyberAcme Upgrades: CyberAcme (CyAc) is the first faction you meet when booting up Marathon. They specialize in basic upgrades that help mitigate some of the early challenges you’ll face on a given run. This includes the ability to buy backpacks, more vault storage space, faster looting speed and more. Our list focuses on helping you get loot/credits quickly while improving your storage limit. Here are the CyAc upgrades you should unlock first: Scavenger.EXE – CyAc Rank 1 Loot Speed increases how quickly items are revealed when looting containers. Requirement: 2,500 credits Informant.EXE – CyAc Rank 2 Increases date card credit rewards by 50%. this bonus additively stacks with other informant upgrades. Requirement: 1,500 credits Heat_Sink.EXE – CyAc Rank 1 Heat Capacity increases the number of movement actions (sprinting, sliding) you can perform before overheating. Requirement: 2,500 credits, 12 Unstable Biomass Expansion – CyAc Rank 3 Gain additional rows of vault capacity for the rest of the current season. + 8 rows Requirement: 2,500 credits, 12 Unstable Diodes Locksmith - CyAc Rank 4 Unlocks Lockbox Key for purchase in Armory Requirements: 2,500 credits Scavenger.EXE 2 - CyAc Rank 4 Loot Speed increases how quickly items are revealed when looting containers. Requirement: 2,500 credits Carrier – CyAc rank 5 Unlocks Enhanced backpacks for purchase in the Armory. + 8 slots. (500 credits) Requirement: 1,500 credits Expansion – CyAc Rank 7 Gain additional rows of vault capacity for the rest of the current season. Requirement: 4,000 credits, 22 Unstable Diode, 12 Unstable Gunmetal NuCaloric Upgrades: The second Marathon faction is called NuCaloric (NuCal). This group specializes in equipping your Runner with better shields, patch kits, and hardware-based consumables. Here, we focused on the upgrades that synergize with our CyAc recommendations; free items to put in your improved vault, the ability to buy better shields, and hardware improvements that mitigate long lasting debuffs. Here are the CyAc upgrades you should unlock first: Safeguard – NuCal Rank 1 Unlocks daily free Shield Chargers in the Armory Requirement: 750 credits, 16 Unstable Biomass Restore – NuCal Rank 3 Unlocks daily free Patch Kits in the Armory. Requirement: 1,500 credits, 23 Unstable Biomass Advance Shields – NuCal Rank 6 Unlocks Advance Shield Chargers for purchase in the Armory. Requirement: 1,500 credits, 8 Reclaimed Biostripping, 10 Unstable Biomass Reinforce.EXE – NuCal Rank 6 Hardware reduces the duration of negative status effects that debilitate your Runner’s physical chassis. Requirement: 1,500 credits, 8 Reclaimed Biostripping, 9 Unstable Biomass MIDA and Sekiguchi Upgrades: The last few factions to worry about are MIDA and Sekiguchi (Sekgen). That’s not to say that Traxus and Arachne don’t have good upgrades. They just aren’t necessarily the best options early on. The other two offer “permanent” hardware boosts and lifesaving consumables. Here are the MIDA and Sekiguchi upgrades you should unlock first: Mida Flex_MATRIX.EXE – MIDA Rank 3 Agility increases your movement speed and jump height Requirement: 750 credits, 16 Unstable Lead Anti-Virus Packs – MIDA Rank 5 Unlocks anti-virus packs for purchase in armory. Requirement: 1,500 Credits, 23 Unstable Lead Spare Rounds – MIDA Rank 8 Unlocks Ammo Crates for Purchase in the Armory. Requirement: 1,500 Credits, 19 Dynamic Compounds, 9 Surveillance Lens Sekgen TAC_Amp.EXE – Sekgen Rank 2 Tactical Recovery reduces the cooldown of your tactical and trait abilities. Requirement: 750 credits, 16 Unstable Diode Fast tracking to these upgrades will certainly benefit new Marathon players. That said, considering how the factions are unlocked and what they offer, it’s possible that some will opt for different options. There’s no real wrong answer…at least, besides improving your vault. No matter what you do, make sure you get Expansion(s) as soon as possible. It won’t take long for you to run out of space and/or be forced to sell items just to be allowed to go back out on runs.

YouTube's new AI slop rating feature sounds reasonable, but it could backfire in several ways. The post YouTube is outsourcing its AI slop problem to you, and that’s a terrible idea appeared first on Digital Trends .