 Android Headlines
Android Headlines

 Mashable
Mashable

 Gizmodo
Gizmodo

 Android Central
Android Central
 Android Headlines
Android Headlines

 Techmeme
Techmeme

 9to5Mac
9to5Mac
 9to5Mac
9to5Mac

 Digital Trends
Digital Trends

 Ars Technica
Ars Technica
 Gizmodo
Gizmodo

 WIRED
WIRED
 Gizmodo
Gizmodo
 Phandroid
Phandroid

 GameSpot
GameSpot
 VentureBeat
VentureBeat
 Gizmodo
Gizmodo
 GameSpot
GameSpot
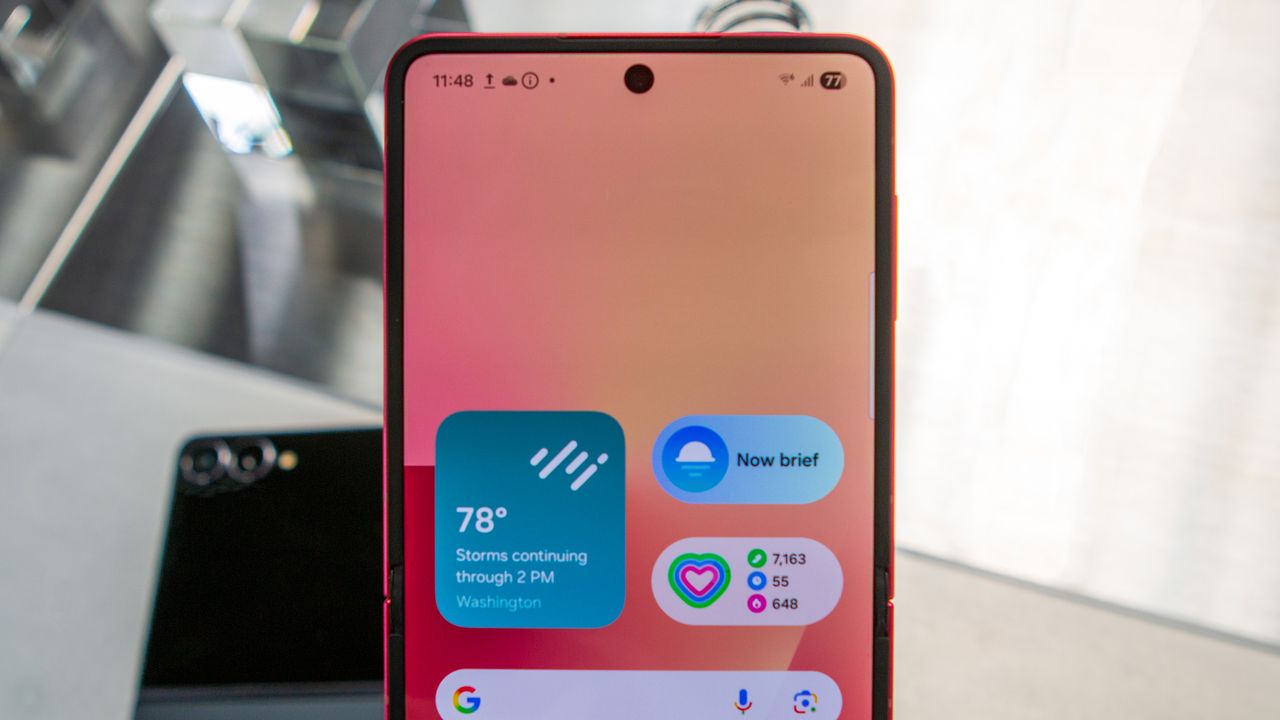 Android Central
Android Central

 Android Authority
Android Authority

 PCWorld
PCWorld
 VentureBeat
VentureBeat

 TechCrunch
TechCrunch
 TechCrunch
TechCrunch
 Digital Trends
Digital Trends
 Techmeme
Techmeme

 TechRadar
TechRadar
 Ars Technica
Ars Technica

 NYTimes Tech
NYTimes Tech
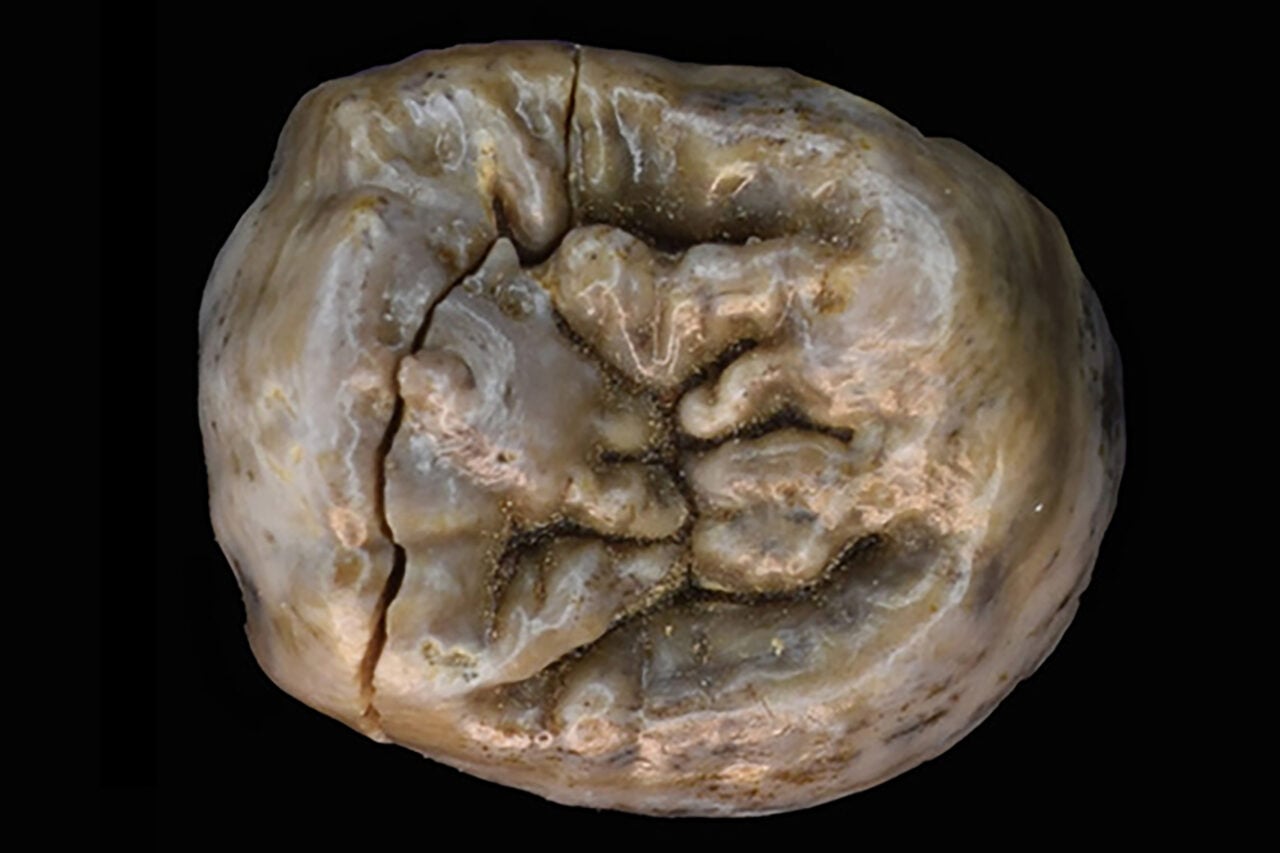 Gizmodo
Gizmodo